Visual Memory Benchmark and Temporal Encoder
Demo#
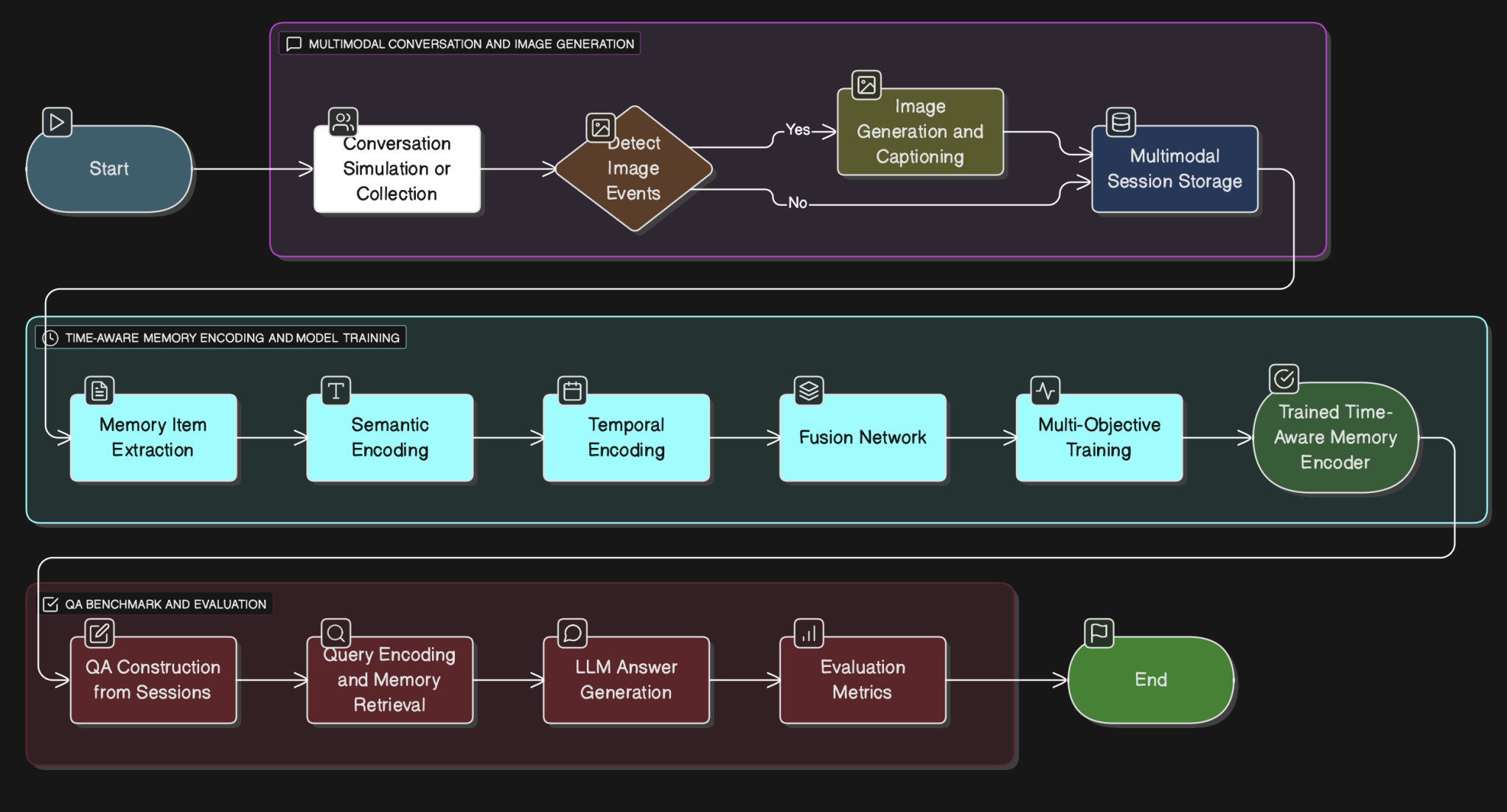
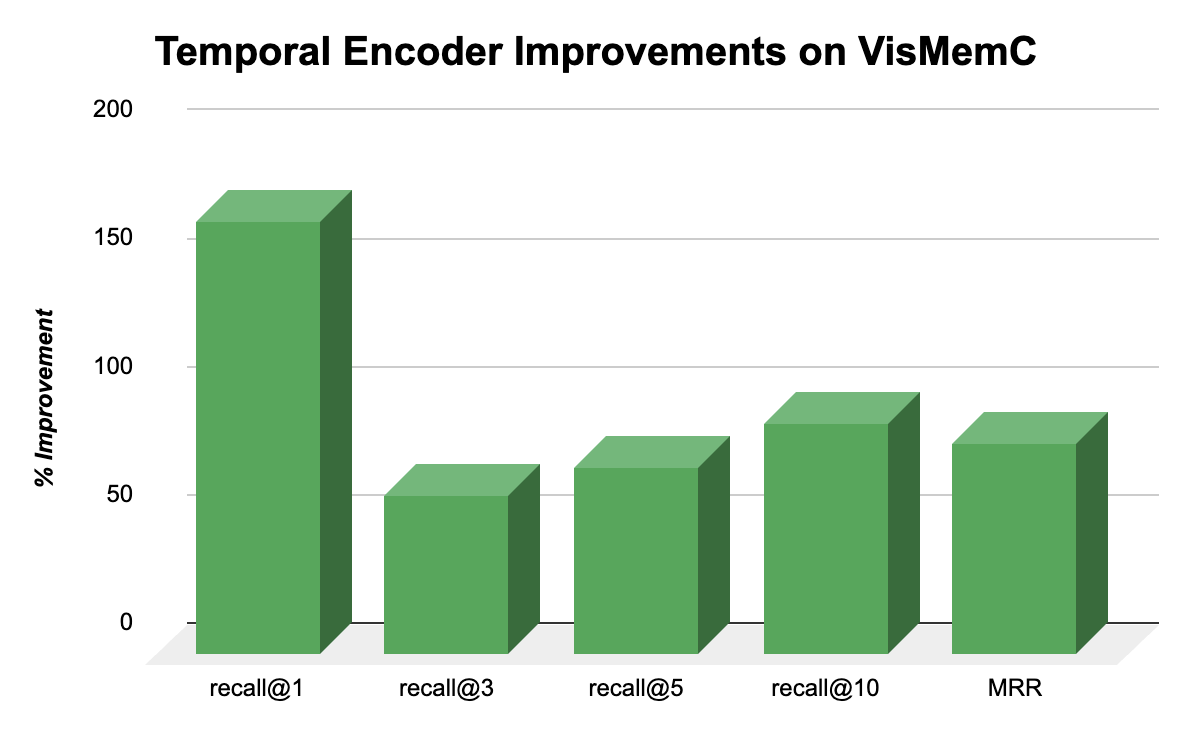
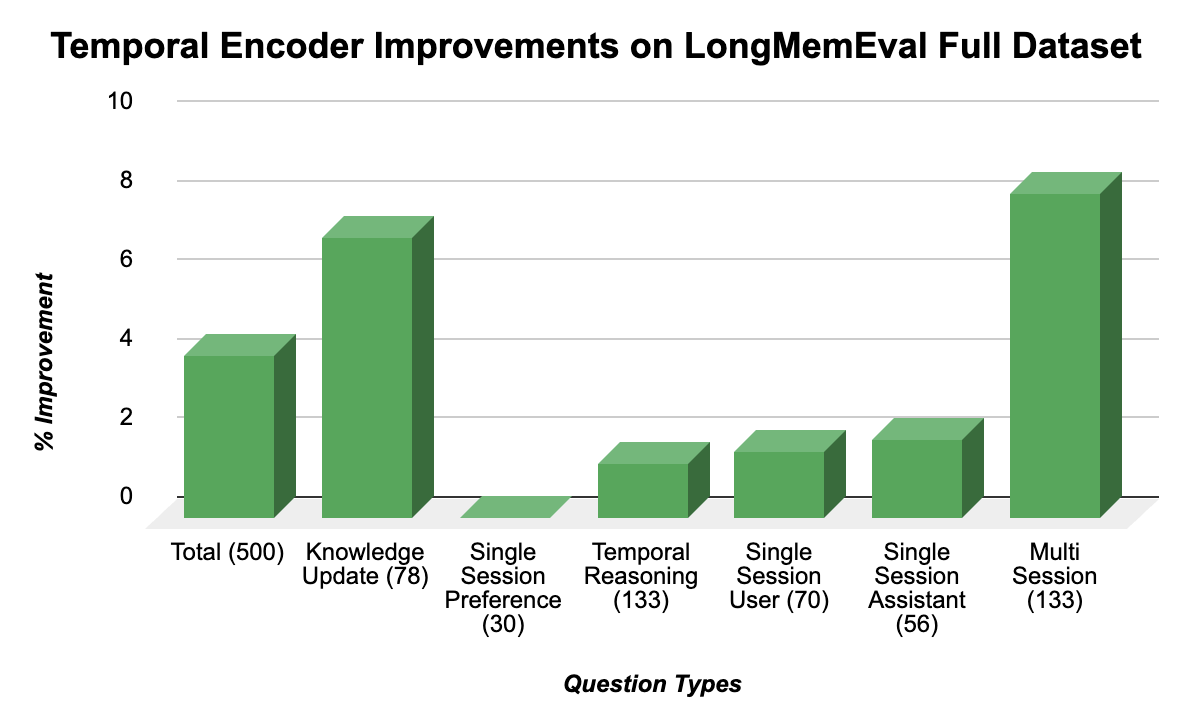
Overview#
VisMemC is a time-aware multimodal memory system and benchmark designed to evaluate AI assistants’ ability to recall and reason over long-term conversational histories grounded in both text and images. The project consists of two components: a benchmark generation pipeline that creates multi-session synthetic dialogues between personas from the MSC dataset enriched with AI-generated images inserted at controlled temporal points, and a temporal memory system that augments semantic embeddings with explicit time encodings. Built using GTE-base encoder, sinusoidal time embeddings, and a trainable fusion network, the system combines semantic, visual, and temporal information for retrieval. The temporal encoder is trained with three complementary loss functions: semantic contrastive loss, temporal proximity loss, and time-window membership loss. Evaluated on both the VisMem benchmark and LongMemEval, the system achieves a 90% improvement in recall@10 (from 10.25% to 19.52%) and an 82% improvement in mean reciprocal rank compared to semantic-only baselines, demonstrating that temporal information provides crucial disambiguation signals for retrieving relevant conversation turns from dialogues spanning thousands of turns.
Why#
Modern AI assistants interact with users over extended periods where important details may appear weeks apart and be grounded in visual content like photographs or receipts. However, existing memory systems overwhelmingly focus on short, text-only contexts and treat temporal structure as auxiliary metadata rather than a core part of reasoning. Traditional retrieval systems ignore temporal distance and ordering, leading to failures on recency questions, chronological comparisons, and temporal reasoning tasks. In long conversations, topics naturally recur—users might mention restaurants or hobbies multiple times across different sessions—and without temporal information, retrieval systems cannot distinguish between semantically similar but temporally distinct events. This project addresses the fundamental limitation that pure semantic similarity struggles when many conversational turns discuss topically related content, but only specific turns contain the exact information needed to answer queries. By incorporating time directly into the embedding space alongside semantic and visual features, the system enables representations that jointly encode when events occurred, how visual observations relate to earlier dialogue, and how a user’s state evolves over time, ultimately enabling more accurate and contextually appropriate responses in long-horizon conversational AI.